“Serverless” Database Is Dead - It’s Time to Evolve

TL;DR
LambdaDB is a serverless-native search engine built entirely on serverless components like AWS Lambda and S3. It completely eliminates the need for infrastructure management by separating database logics from entire infrastructure. LambdaDB provides powerful vector, full-text, and hybrid search with filtering and sorting, plus enterprise-grade features like point-in-time restore and zero-copy cloning, all with zero infrastructure management. LambdaDB is 10x cheaper than alternatives such as Elastic and Pinecone, scales instantly zero from practically infinite, and is BYOC(Bring Your Own Cloud)-friendly by design.
Ready to experience LambdaDB?
- Try it now: https://docs.lambdadb.ai/guides/get-started/quickstart
- Try playground: https://share-na2.hsforms.com/1vBeXGa1ETXupo4_mIrtoEA40td9f
- Join our community: https://discord.gg/6qtmgtj342
Otherwise, read on to learn more!
The Illusion of “Serverless” Database
“Serverless” has become a core trend in cloud technology. It’s a revolutionary paradigm that allows developers to focus solely on business logic without the burden of server management. The core value is simple: you pay only for what you use, and operational overhead is virtually zero.
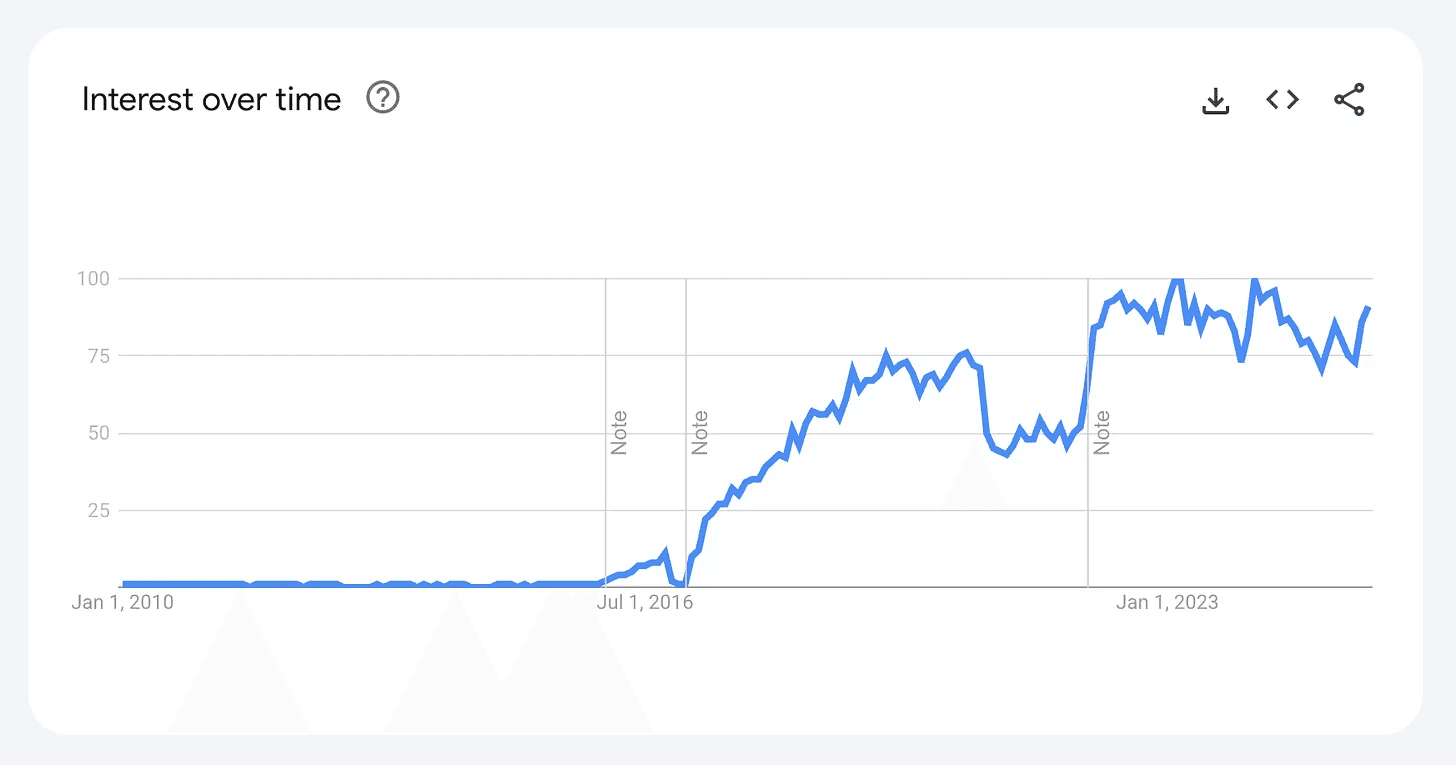
Google Trends for serverless computing (2010 — present)
In line with this trend, numerous “serverless" databases have entered into the market. Existing leaders like Elastic, Confluent, and Pinecone, as well as new challengers like Neon, WarpStream, Upstash, and Turbopuffer, are all competing with serverless offerings.
But here’s the hidden truth: look under the hood, and you’ll find they aren’t truly serverless. Most of these services are built on a cloud-native architecture, a brilliant but decade-old design that separates compute clusters from cloud storage. This model, pioneered by Snowflake [1], was a revolution for the serverful era. But it was never designed for modern serverless components like AWS Lambda.
As a result, providers create an illusion of serverless. Behind the scenes, they are still running clusters of servers, using complex software and human intervention to predict load, manage capacity, and ensure reliability.
Why This Mismatch Matters to You
This architectural mismatch isn’t just a technical detail — it creates real problems for users (see [2, 3, 4, 5] for examples):
- You’re paying for idle servers: Their server clusters are always running for various purposes, from handling requests to performing background tasks. This is why most “serverless” plans come with monthly base fees and significant cost increases as usage grows — costs that don’t truly reflect your actual usage.
- Scaling is slow and capped: Spinning up new servers in a cluster takes minutes, not milliseconds. Providers often scale down conservatively, leaving resources idle even longer to avoid performance issues. This sluggishness means you can’t handle sudden traffic spikes instantly, and you’ll often face restrictive limits on data size and requests.
- You have limited options: Because providers need to manage infrastructure for each cloud region, you typically have only a few service regions to choose from. If you want to run the database in your own cloud account (BYOC), you're most likely forced into complex and expensive enterprise contracts.
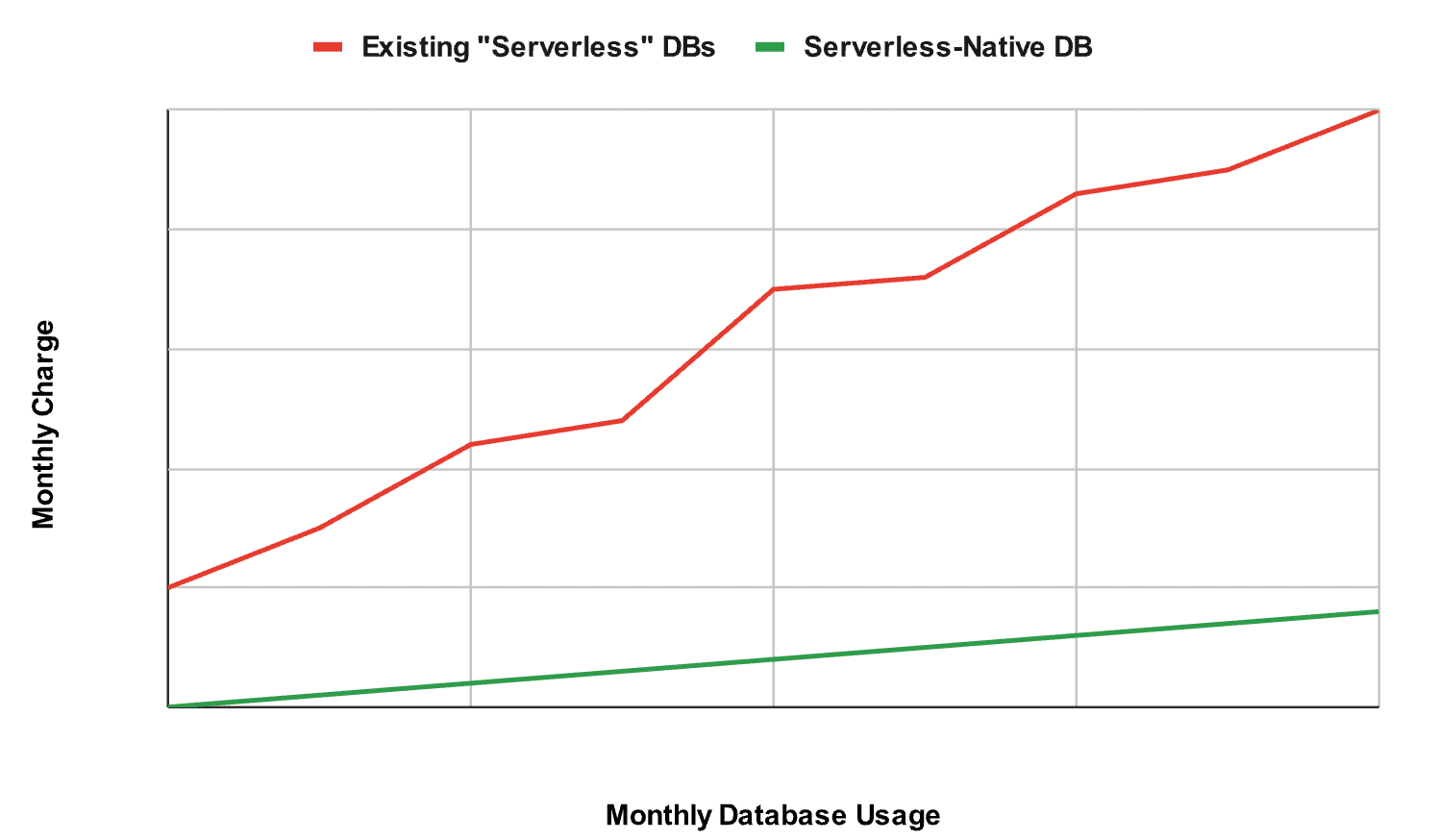
Monthly charges as database usage grows: ideal vs. reality.
An Unsustainable Model for Everyone
Ultimately, “serverless” databases built on serverful architecture are unsustainable — both for you and the provider.
Providers need significant investor funding just to operate server clusters for thousands of mostly idle databases. To make up for these costs, they are eventually forced to change their pricing [6]. The result? Light users are overcharged to subsidize the system, and successful users are hit with steep, unpredictable price hikes as they scale.
The Real Solution: Serverless-Native Architecture
In the early days of cloud computing, most “cloud" databases were just legacy databases running on cloud VMs with local disks. It took a decade for a truly cloud-native architecture to emerge and unlock the full potential of the (serverful) cloud.
Now, nearly a decade after AWS Lambda’s launch, we are at another inflection point. The solution isn’t to put a serverless sticker on old architecture. It’s to build differently from the ground up. We call this new approach serverless-native.
A serverless-native architecture shifts all infrastructure management to the cloud provider. Instead of server clusters, it relies entirely on stateless functions and serverless services. This shared-everything approach treats the cloud infrastructure as a single massive supercomputer — a true cloud-scale computer. By completely separating database logic from infrastructure, the system can scale instantly and operate on a genuine pay-per-request model without minimum charges or hidden costs.

Here's a simple litmus test to identify if a database is truly serverless-native: Can you deploy it into a cloud account without provisioning a Kubernetes cluster, a single VM, or any other compute servers? If the answer is no, it's not serverless-native.
Of course, building a high-performance database this way presents a unique set of challenges. You must architect a consistent, distributed system on top of inherently ephemeral compute resources. You have to orchestrate concurrent reads and writes over high-latency object storage (S3) and work within the resource limits of individual functions. Additionally, you need to consider different pricing models for various serverless components to create a cost-effective solution. These are the hard problems we have focused on solving.
Introducing LambdaDB: The First Serverless-Native Database
LambdaDB is a new search engine built from first principles to be serverless-native. It provides powerful vector, full-text, and hybrid search with filtering and sorting, plus enterprise-grade features like point-in-time restore and zero-copy cloning, all with zero infrastructure management.
LambdaDB operates as a collection of serverless functions and resources within AWS, completely separating database logic from infrastructure. User requests flow through a regional Gateway, which routes them to either Control or Data Functions. Builder Function periodically persists all buffered data to S3 storage.
How It Works: A Look Inside LambdaDB
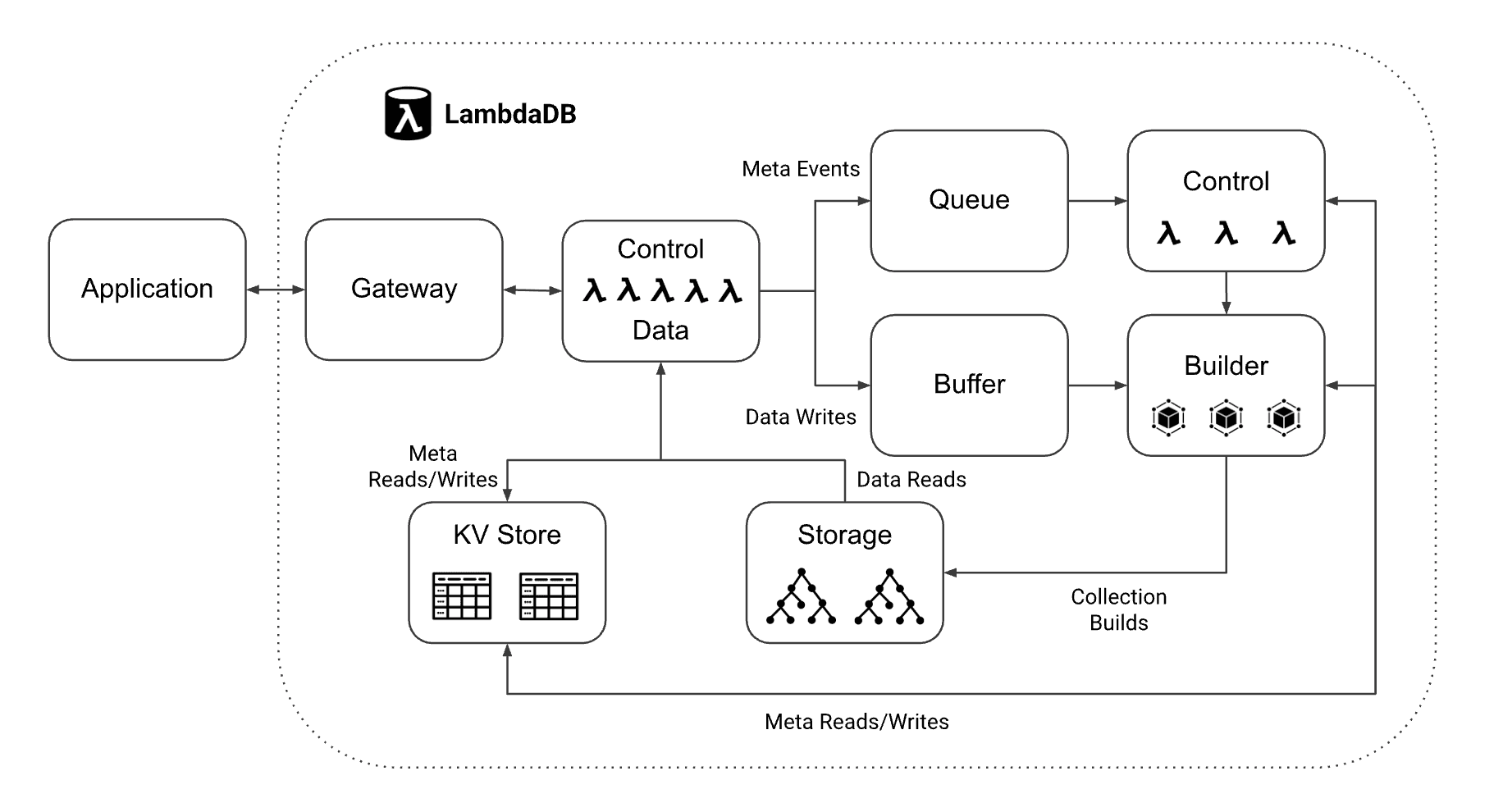
The LambdaDB architecture: All components are built on serverless cloud services
Gateway verifies the project API key in user requests for targeted projects. If the key is valid, it checks whether the project exceeds its configured rate limit. It then routes the request to either Control or Data Functions, based on the type of work needed.
Control Functions handle project/collection CRUD operations and data management requests such as point-in-time restore and zero-copy clone. They also performs maintenance tasks, such as adjusting the number of virtual shards for each collection to enable parallel query execution based on collection size, triggered by EventBridge Scheduler. They use DynamoDB for storing metadata and conducting distributed coordination among concurrent readers, writers, and background tasks.
Data Functions perform actual data writes and reads.
The Write Path. When Writer Function receives a request to upsert, update, or delete records in a collection, it records the request details in a log along with a monotonically increasing sequence number. This request log is written into a durable, serverless write buffer (EFS) before returning a response to the client. Later, Builder function writes the buffered logs to S3 in batches and deletes them once the data is successfully committed. In S3, the data is organized as a tree structure where a root object contains intermediate objects pointing to leaf objects that store the actual data. So the root object basically acts like commit point that always contains a consistent collection view. This on-storage structure, combined with S3 versioning and lifecycle policies, enables us to implement multi-version concurrency control and advanced features like point-in-time restore efficiently and robustly without reinventing the wheel.
The Read Path. When a query is received, Router Function validates it and then invokes Executor Functions based on the number of virtual shards assigned to the collection by a control function. If the client specifies strong consistency, the router also runs the query against buffered logs. Each executor scans its assigned shard data and returns a list of top candidates to the router. The shard data is typically cached in the executor’s memory and local storage. If data isn’t cached, the executor fetches it from S3 in block units and caches it for future queries. The router then compiles all results, merges and deduplicates them with results from buffered logs if needed, selects the final top_k candidates and returns them to the client.
But Isn’t Serverless More Expensive?
Counterintuitively, LambdaDB reduces compute costs compared to serverful databases, even though Lambda’s per-unit price is higher than an EC2 instance. This cost advantage exists because at least two readers and two writers are required to ensure high availability and fault tolerance in production deployments — redundancy that isn’t necessary with Lambda. Furthermore, most provisioned capacity is wasted due to high peak-to-average load ratios, buffer capacity for traffic spikes (e.g., Black Friday), and inefficiencies in auto-scaling systems [7]. In reality, average compute utilization in the enterprise often sits at a mere 10–20%, meaning serverless compute can save 50–90% in costs [7].
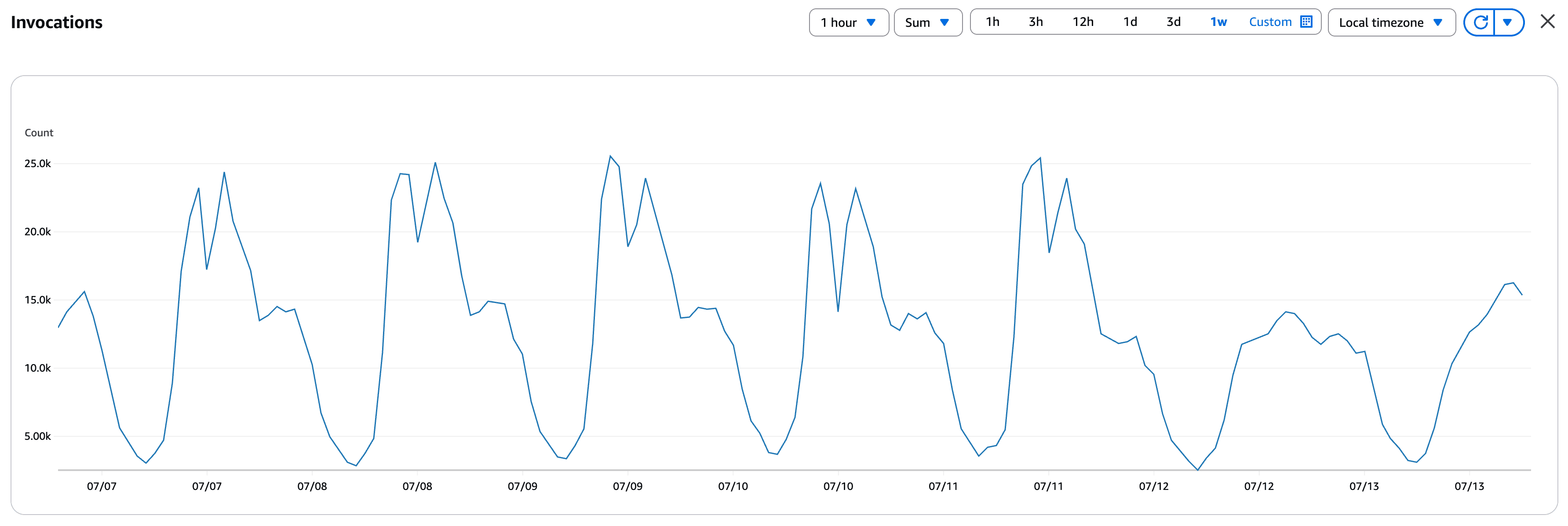
Query function invocations over a one-week period for a production service
This chart shows traffic variation over a week for a real-world search application. As expected, weekday traffic is higher than weekend traffic, and daytime traffic is much higher than overnight traffic. Specifically, the peak traffic during a day is about 7x higher than the lowest traffic. Interestingly, traffic drops sharply at around 12 PM on weekdays due to lunch breaks. In this case, combined with the cost efficiency of S3, LambdaDB could reduce infrastructure costs by 90% compared to a serverful search engine in production.
Performance That Scales 🚀
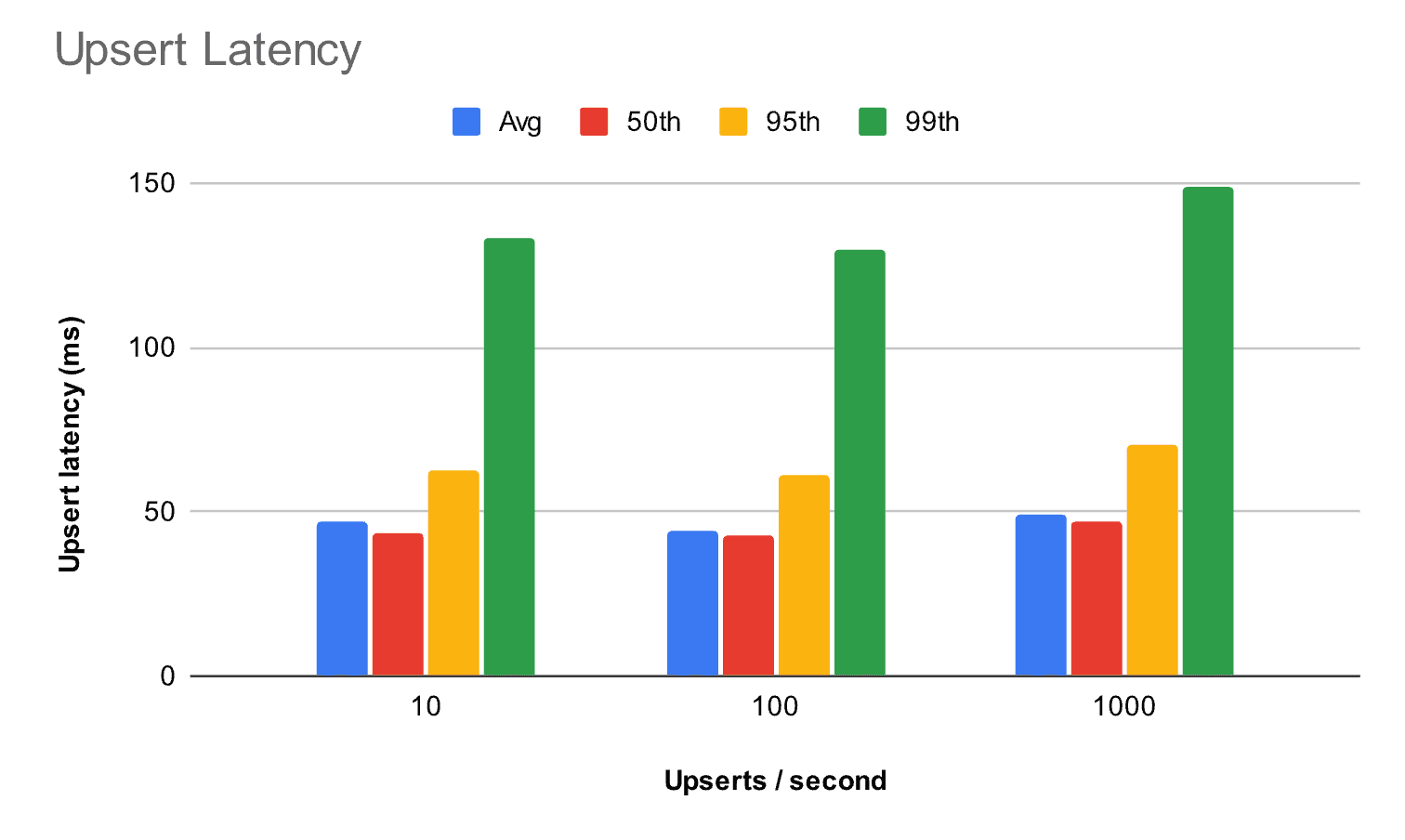
Upsert latency distribution as concurrency increases using 960 dimensional vectors
To demonstrate LambdaDB’s performance and scalability, we added one million 960-dimensional vectors to a collection with varying concurrency levels. With 10 upserts per second, the median latency is just 43 ms with a very short tail (133 ms at the 99th percentile). Write scalability is particularly impressive, as the latency remains similar even when traffic increases 100-fold.
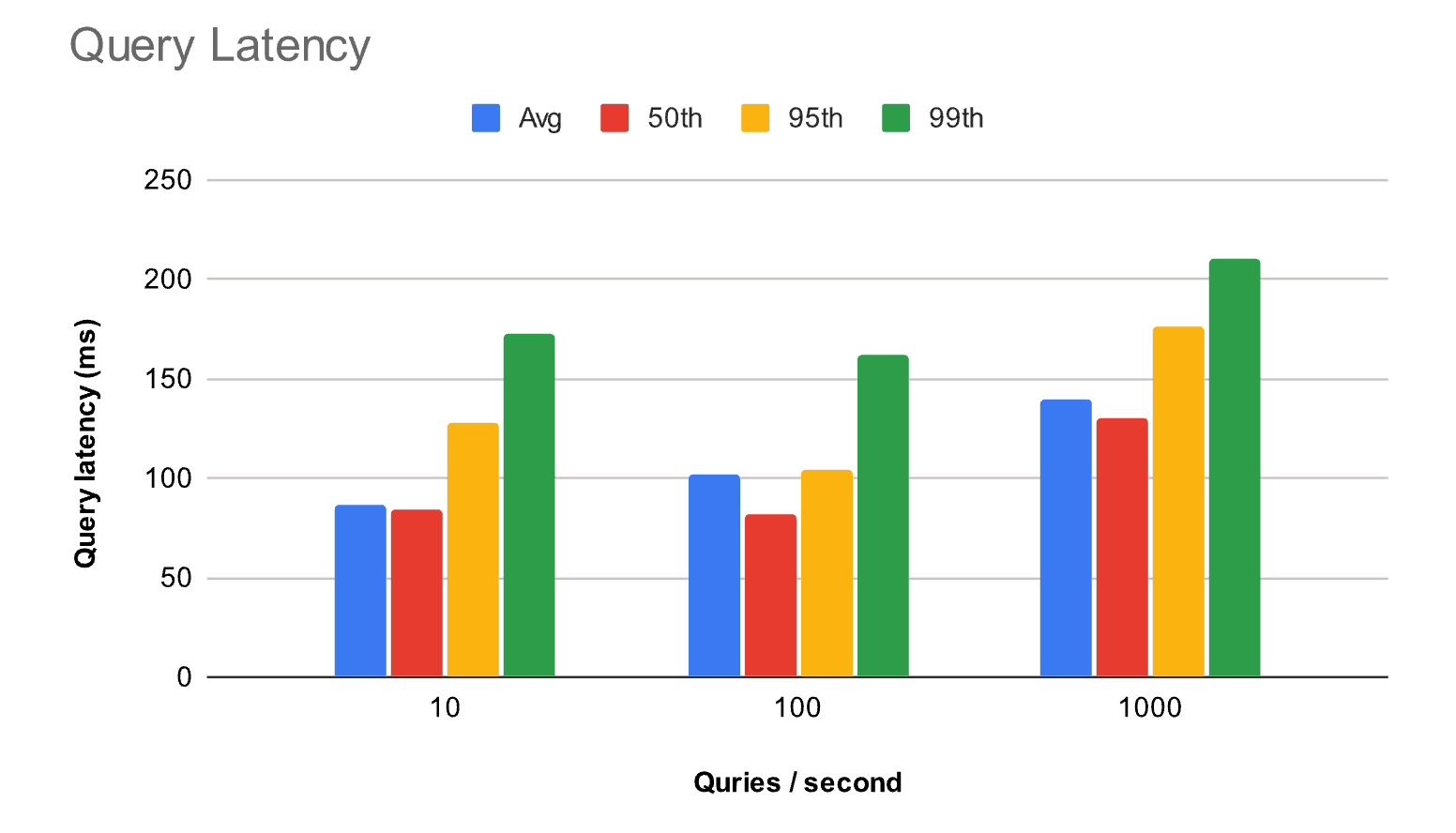
Query latency distribution as concurrency increases using 960 dimensional 1 million vectors
Similarly, query latency remains stable and scalable under varying loads — the 99th percentile ranges from 172 ms to 210 ms. You may occasionally experience a few seconds of latency due to function cold starts, but our production data shows this happens in less than 0.01% of invocations. We’re continuously optimizing query functions to improve both cold and warm latency, and serverless infrastructure is also improving [8, 9, 10]. For most applications, the current performance is already excellent, and the cost savings easily justify the rare latency spike.
Your Benefits, Summarized
Our unique architecture provides tangible benefits:
- Dramatically lower costs: With no idle servers to pay and manage for, LambdaDB is 10x cheaper than leading alternatives like Elastic and Pinecone. You only pay for the requests you make and the storage you use.
- Truly instant & infinite scale: LambdaDB scales from zero to thousands of parallel functions in milliseconds to handle any traffic spike without configuration.
- Simple to start, simple at scale: Build powerful AI applications with rich search capabilities. As you grow, the architecture remains just as simple and cost-effective.
- Advanced features, out of the box: Get enterprise-grade capabilities like point-in-time restore and zero-copy cloning (for safely developing and testing with production data) without the enterprise-grade complexity or cost.
LambdaDB is already serving millions of requests daily across billions of documents with zero management. This is just the beginning. In the long term, we plan to support other data models — including relational data, stream, key-value, and graph — all with the same serverless-native architecture.
Ready to get started?
- Try it now: https://docs.lambdadb.ai/guides/get-started/quickstart
- Apply for early access: https://lambdadb.ai/early-access
- Join our community: https://discord.gg/6qtmgtj342
References
[1] The Snowflake Elastic Data Warehouse, 2016.
[2] 3 AM thoughts: Turbopuffer broke my brain, 2025.
[3] total IO 0, but Aurora serverless costs too much, Is it really true that it works with scale to 0?, 2025
[4] Serverless OpenSearch seems like a huge deal, but am I crazy about the pricing?, 2022.
[5] AWS OpenSearch SearchOCU keeps hitting the max limit, 2025.
[7] Debunking serverless myths, 2018.
[8] New – Accelerate Your Lambda Functions with Lambda SnapStart, 2022.
[9] AWS Lambda functions now scale 12 times faster when handling high-volume requests, 2023.
[10] AWS Lambda SnapStart for Python and .NET functions is now generally available, 2024.
Try LambdaDB on your own workload
$0 to start. $0 at idle. Pay per query. First collection in five minutes.