



Serverless AI Database
for Agents & RAG
Unify full-text, multi-vector, and hybrid search on a flexible document model. Handle infinite persistent memory and massive concurrency instantly— at 1/10th the cost.
Used to buildLLM wikisAgent memoryRAG apps
No credit card·No minimum charge
Proven at scale
1M Vectors in 19s
Ingest throughput (MB/s)
LambdaDB1080 MB/s
Elastic135 MB/s
Pinecone117 MB/s
S3 Vectors100 MB/s
* Performance Benchmarks vs Pinecone Serverless, Elastic Search Serverless, and S3 Vectors. Measured December 2025 against published configurations.
Platform
Built for Agents and RAG
Hybrid Search on a Flexible Document Model
Perform multi-field vector search across text and images simultaneously — without flattening your schema.
Store vectors, keywords, and nested objects in a single document.
Python
query = { "rrf": [ # Keyword search on raw text {"queryString": {"query": user_query, "defaultField": "text"}}, # Semantic search on text embeddings {"knn": {"field": "text_vector", "queryVector": q_vec, "k": 5}}, # Semantic search on image embeddings {"knn": {"field": "image_vector", "queryVector": q_vec, "k": 5}} ] } coll = client.collection("assets") results = coll.query(query=query, size=5)
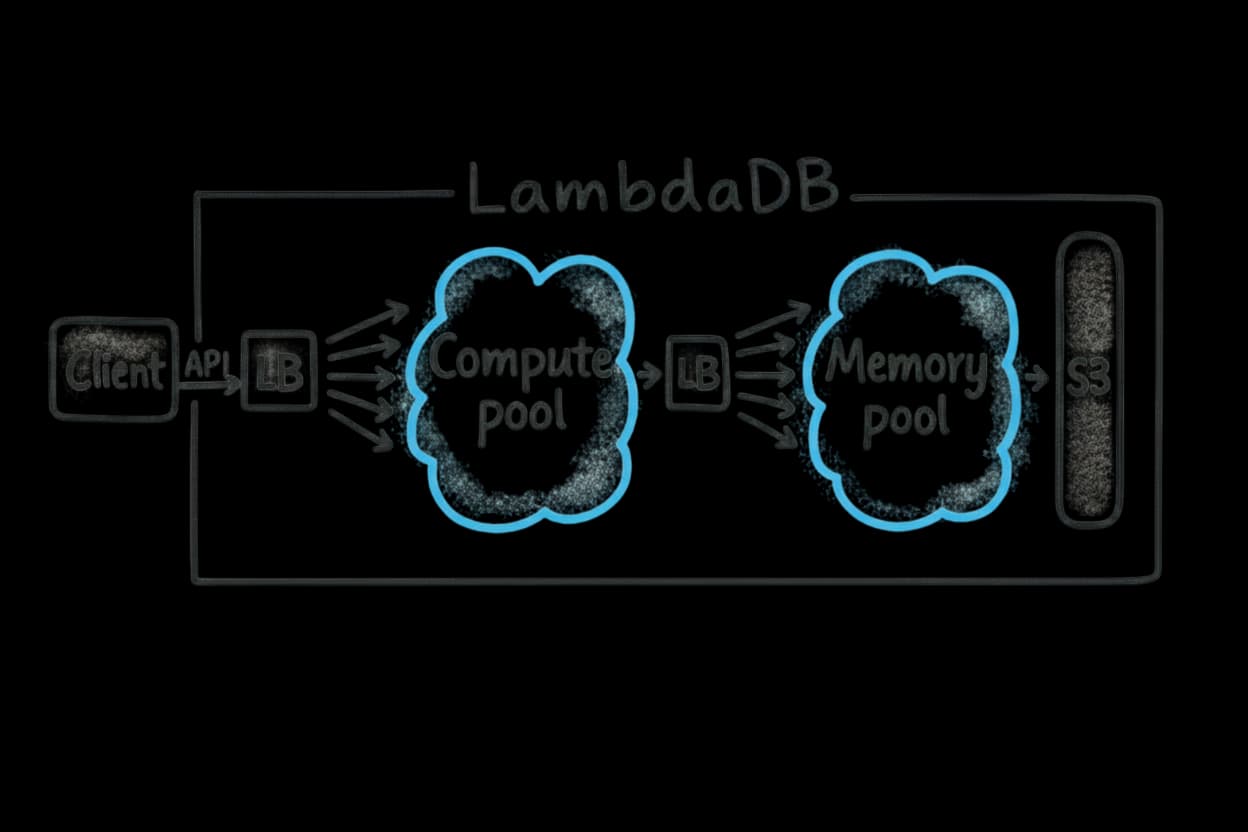
Serverless Elasticity for Agent Storms
Compute, memory, and storage scale independently, with automatic shard scaling.
A single RAG query or a swarm of recursive agents — our disaggregated architecture stays stable either way.
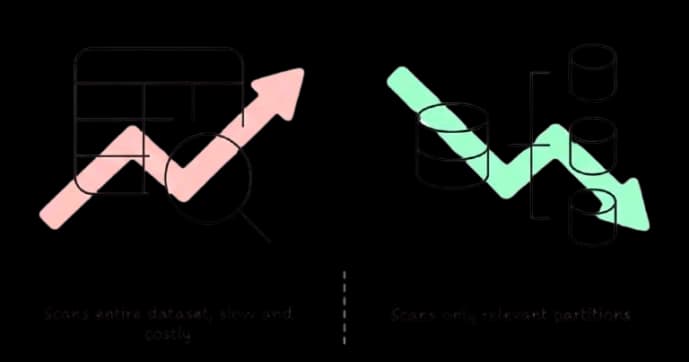
Zero-Waste Scoped Retrieval
Retrieve only the partitions you need — by tenant or category.
Pay only for what you read. Never for idle infrastructure.
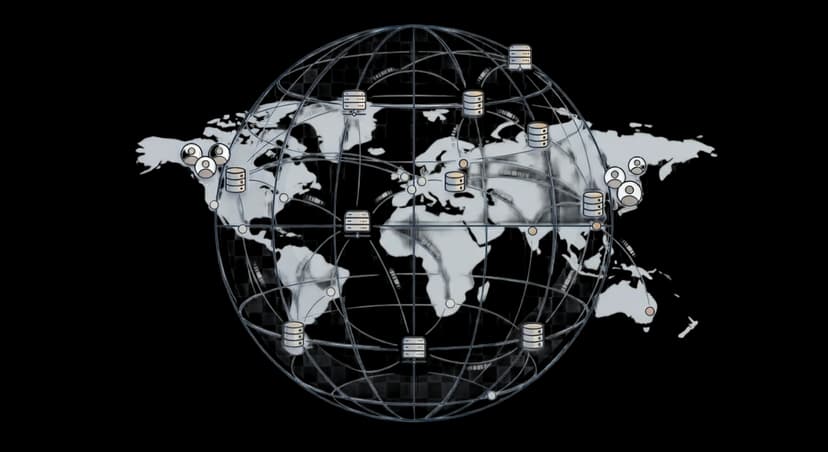
Deploy to 30+ regions worldwide
Deploy anywhere your service runs.
Your data stays where your users are.
Git-like Branching for Collection Data
Fork your production index in seconds to test new embedding models or hybrid weights.
Apply to production only when validated.
Comparison
Why teams choose LambdaDB
Serverless-native vector search. No idle costs, no ops burden, no surprises.
LAMBDADB | PINECONEPINECONE | TURBO-PUFFERTURBOPUFFER | MILVUSMILVUS (ZILLIZ) | |
|---|---|---|---|---|
| Monthly minimum | $0 | $50 | $65 | Free (self-hosted) |
| Deployment | Serverless | Pod-based, Serverless, BYOC | Serverless, BYOC | Self-hosted, serverless |
| RegionsServerless region availability | 34 regions | 3 regions | 9 regions | 2 regions |
| Index types | Dense & sparse vectors, Lucene-syntax full-text, multiple vector fields | Dense & sparse vectors | Dense vector, full-text (BM25) | Dense & sparse vectors, full-text (BM25), multiple vector fields |
| Real-time retrieval | Configurable strong consistency | Not guaranteed | Not guaranteed | Configurable strong consistency |
| Write throughputWrite throughput per collection | >1 GB/s | 117 MB/s | 32 MB/s | 10 MB/s |
| BranchingData branching | ||||
| Partitioning | ||||
| Auto shardingAutomatic sharding | ||||
| Backup & PITRContinuous backup & PITR |
* Comparison sourced from each vendor’s public documentation.
LambdaDB supports developer
friendly experience
Start coding instantly with our simple SDK. Seamlessly integrates with AI ecosystem.
# 1. Install LambdaDB $ pip install lambdadb # 2. Initialize Client from lambdadb import LambdaDB, models with LambdaDB( project_api_key="your_api_key_here", base_url="YOUR_BASE_URL", project_name="YOUR_PROJECT_NAME", ) as client: print("🚀 Connected to Serverless Node")
Pricing Calculator
No clusters. No provisioning. No idle cost, ever.
Storage50GB
06253k6k10k
$16.50@ $0.33 / GB
Writes10GB
01255001k2k
$10.00@ $1.00 / GB
Reads0.1PB
062556100
$0.50@ $5.00 / PB
Minimum charge comparison
LambdaDB$0 minimum
Turbopuffer$64.00 / mo
Pinecone$50.00 / mo
Weaviate$45.00 / mo
Estimated monthly cost
$27.00/ month
No minimum chargeCost breakdown
Storage $0.33/GB$16.50
Writes $1.00/GB$10.00
Reads $5.00/PB$0.50
Total$27.00
Included in every plan
- Pay-as-you-go based on usage
- Choose a right region next to your service area
- Continuous backup and point-in-time-restore
- Hybrid search + semantic + lexical
- Zero-copy collection fork
View full pricing No credit card required to get started
Stay on the Frontier


Start simple. Scale to billions.
Discover how LambdaDB keeps your AI fast and affordable as your data grows.