Why AI Agents Should Sleep Cheap

TL;DR
- An AI agent is busy for ~1% of its life. The other 99%, it's waiting. For the user to type, for a cron to fire, for a webhook to arrive.
- Most vector databases charge you for that 99%. Pinecone Serverless now has a $50/mo project minimum, and one customer watched a $50 bill turn into $2,847 in a single month as usage scaled.
- That math only exists because the database is sitting on a server. Take the server away and idle cost collapses to $0.
- LambdaDB runs entirely on serverless components. No instance to keep warm. Storage is cheap, compute is per-request, and an agent that never wakes up costs you nothing.
- Code below shows the full memory loop. Copy, paste, ship.
The math that kills side projects
If you're building an AI agent (coding assistant, support bot, personal helper, research crawler) you've seen this thread on Reddit and Hacker News. We get it in our inbox too:
"Pinecone's new $50/mo minimum just nuked my hobby project."
"$50 to $380 to $2,847 in three months."
"Vector database costs that scale linearly with usage don't align with predictable infrastructure budgets."
I've kept those quotes on a wall since we started LambdaDB. They're real, and they're strangely polite about what's happening. Here's the less polite version.
There are two cost problems, and they hit you at different stages.
The floor kills you on day zero. Pinecone's Standard plan now has a $50/mo project minimum. Side project, indie experiment, validating an idea. Doesn't matter. That's the price of zero users, before anyone has typed a single message. One developer summed it up: "I generally managed to keep my bills under US$10. By storing only the most essential data in the Vector DB." That option is gone.
Then linear-scaling metering kills you at growth. Past the floor, the bill grows with usage. The customer who went $50 → $2,847 wasn't doing anything exotic. It was a RAG-based support chatbot. Read units, storage, write operations, all metered. As one HN commenter put it: "it's extremely hard to dilute pricing into a simple equation like $x/months because sometimes there are multiple variable parts."
Either failure mode wrecks the unit economics of an agent product. Same shape both times: the bill is shaped like a server, but the workload isn't.
This is what I mean when I say agents should sleep cheap. The product hasn't started yet. The user hasn't typed yet. The model hasn't been called. And your invoice is already growing. For compute that didn't run.
Why AI agents are idle 99% of the time
People model AI agents like web servers. Always on, always serving traffic. That model is wrong.
A coding agent is busy when you're paired with it. Then it sits there for 8 hours while you sleep. A support agent is busy when a ticket arrives. Then it waits for the next one. A scheduled research bot runs once a day and is dead the rest of the time.
Even being generous, the duty cycle of an individual agent looks like this:
Active: ~1% of wall-clock time
Idle: ~99% of wall-clock time
This isn't a bug. It's what an agent is. An AI agent is an event-driven workload pretending to be a service.
The infrastructure underneath should match that shape. If your storage layer charges per hour of "the index exists" (or imposes a monthly floor before you've sent a single request) you're paying for 99% of nothing.
What "serverless" was supposed to mean
Most vector databases sell a "serverless" tier today. Look at the bill and you'll notice they kept the server. They put a router in front of a fleet of warm pods, called it serverless, and rounded up to a minimum monthly charge so the pods would still be there when you came back.
That's a managed service. It's not a serverless one. As one developer wrote in a thread about the Pinecone price hike: "True serverless architecture requires building on serverless primitives rather than just putting a serverless API on top of server clusters." The $50/mo floor was the proof. Fixed internal cost being passed through.
A real serverless vector database has three properties. Compute is created on the request and destroyed after. No instance to keep warm. Storage and compute are decoupled, so you pay storage bytes per month and compute milliseconds per request as separate line items. And idle cost is $0. No requests, no compute, only storage.
LambdaDB is built this way because it has to be. The whole engine uses per-request compute and decoupled object storage. No fleet. No warm pods. When your agent goes to sleep, the only thing still ticking is the bytes its memory occupies in storage. Measured in cents per gigabyte per month, not dollars per project per month.
That's why we can charge per query and start at $0. The architecture allows it. Server-based competitors can't follow without rewriting the product.
Inside LambdaDB in three boring boxes
Quick, because the cost story is the interesting part.
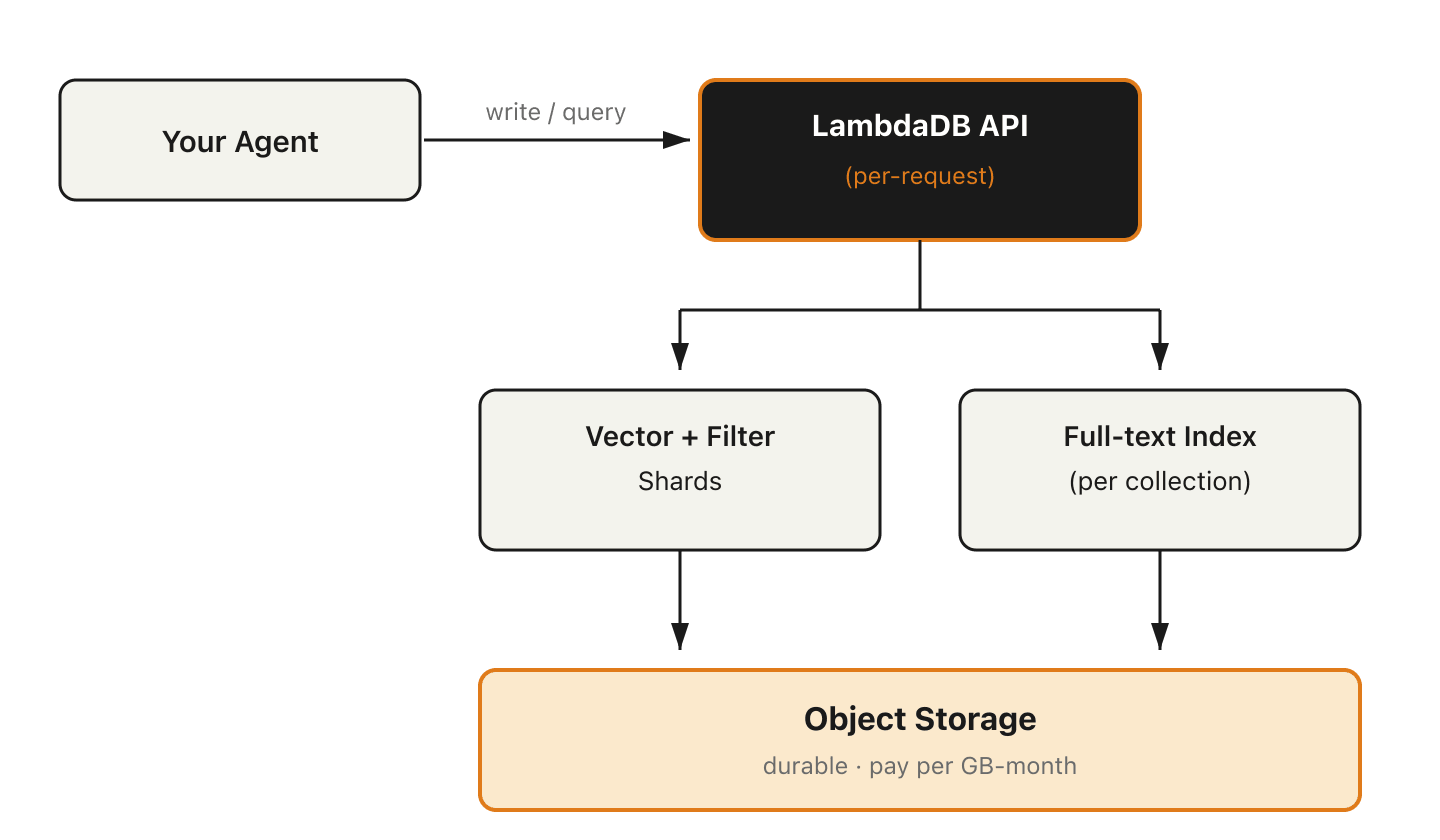
A request hits the API. A per-request worker spins up, reads the relevant shard from object storage, runs the hybrid search (vector + full-text + filter in one query), returns the result, and goes away. Cold start is sub-second for typical agent payloads. We keep enough infra primed at the platform level that user-perceived p99 latency stays in the same envelope as a "warm" managed DB for the write-then-read patterns agents run. Storage is decoupled object storage. The idle cost for an entire agent's memory (say, 50 MB of vectors and metadata) is rounding error.
What this looks like for your wallet, before any usage:
Pinecone Standard plan, project minimum: $50.00 / month
LambdaDB project, idle (~50 MB): $0.001 / month
Three orders of magnitude. And that's just the floor. Above it, both products meter usage; the difference is that LambdaDB's floor is the storage you used, not a fixed monthly charge to keep a fleet warm.
How LambdaDB compares for agent memory
| LambdaDB | Pinecone Serverless | Qdrant Cloud | Weaviate Cloud | |
|---|---|---|---|---|
| Project minimum | $0 | $50/mo (Standard plan floor) | Cluster-billed (always-on) | Cluster-billed (always-on) |
| Compute model | Per-request | Warm pods + router | Provisioned cluster | Provisioned cluster |
| Storage backend | S3 | Proprietary | Block storage | Block storage |
| Free tier | Pay-as-you-go from $0 | Limited starter | 1GB cluster | Sandbox only |
| Best fit | Many idle agents, per-user memory | High-QPS single-tenant search | Self-hosted-style control | Hybrid + GraphQL |
Every "serverless" tier in the market keeps the server somewhere. Either as a warm-pod fleet behind a router, or as an always-on cluster you provision. Only serverless components takes the server away.
What about pgvector?
Most-asked counter-question on Hacker News, and the honest answer: if your dataset fits comfortably in your existing Postgres and you have one service querying it, pgvector is fine. "Show me what I can't do in pgvector" is a fair challenge, and most teams under ~1M vectors and one app shouldn't bother switching.
Where pgvector breaks down is the shape this post is about. Many small, mostly-idle, per-user namespaces. Postgres wants one HNSW index that fits in RAM. You don't get one HNSW index per user without paying for a lot of RAM. That's the workload that needs a different storage substrate, and that's the workload serverless components fits.
If you're not in that workload, stay on Postgres. I'd rather you keep your stack simple than switch for the wrong reason.
How to build agent memory: full TypeScript example
Promised you agents that sleep cheap. Here's the whole memory loop. Copy and paste.
Install:
npm install @functional-systems/lambdadb
Set up a memory collection shared across users. Filter by user_id on every query so each user only sees their own memory. And a single delete by filter call wipes a user's data when needed.
import { LambdaDBClient } from "@functional-systems/lambdadb";
const client = new LambdaDBClient({
projectApiKey: process.env.LAMBDADB_API_KEY!,
baseUrl: process.env.LAMBDADB_BASE_URL!,
projectName: process.env.LAMBDADB_PROJECT!,
});
await client.createCollection({
collectionName: "agent_memory",
indexConfigs: {
content: { type: "text", analyzers: ["english"] },
vector: { type: "vector", dimensions: 1536, similarity: "cosine" }, // text-embedding-3-small
user_id: { type: "keyword" },
role: { type: "keyword" }, // user | assistant | system
created_at: { type: "keyword" },
},
});
const memory = client.collection("agent_memory");
Write a memory on every turn:
async function remember(userId: string, role: string, content: string) {
const [vector] = await embed([content]); // your embedding call
await memory.docs.upsert({
docs: [{
id: crypto.randomUUID(),
content,
vector,
user_id: userId,
role,
created_at: new Date().toISOString(),
}],
});
}
Read relevant memory on the next turn. Hybrid search (vector + full-text + filter in one request) which is what you want when an agent reasons over its own past. (Pure vector search will happily return "Error 222" when you asked about "Error 221"; full-text catches the literal match.)
async function recall(userId: string, query: string, k = 8) {
const [queryVector] = await embed([query]);
const result = await memory.query({
size: k,
query: {
rrf: [
{ queryString: { query, defaultField: "content" } },
{ knn: { field: "vector", queryVector, k } },
],
},
filter: {
queryString: { query: `user_id:${userId} AND (role:user OR role:assistant)` },
},
consistentRead: true,
});
return result.docs.map(h => ({
role: h.doc.role,
content: h.doc.content,
score: h.score,
}));
}
Glue it into a turn:
async function turn(userId: string, userMessage: string) {
const memories = await recall(userId, userMessage);
const response = await llm.chat({
messages: [
{ role: "system", content: buildContext(memories) },
{ role: "user", content: userMessage },
],
});
await remember(userId, "user", userMessage);
await remember(userId, "assistant", response.content);
return response.content;
}
That's the whole loop. Nothing to provision before it works. No monthly minimum sitting under it. If turn() never gets called, the only thing on your bill is the bytes the memory takes up in storage.
If 10,000 of your users go quiet for a week, your idle cost for that week is roughly the cost of a coffee.
What changes when idle cost is $0
Once idle cost goes to zero, you start designing differently.
Per-user namespaces become normal. When the platform charges a $50/mo floor or per-pod overhead, you cram everyone into one index and reinvent multi-tenancy in your application code. When namespaces are free, you give every user their own. Deletes become trivial. Privacy boundaries become trivial. GDPR-style data deletion becomes one API call.
Agent fan-out becomes affordable. Spawn a research sub-agent with its own memory namespace, let it run for an hour, throw it away. The cost is the requests it made, nothing more. No fleet "we kept around just in case."
Long-tail products become viable. The hobby project that only wakes up when someone hits the URL? It costs roughly nothing when nobody uses it and pennies when someone does. The economics that nuked indie AI projects under the Pinecone floor stop applying.
And you can keep more memory. Most teams I talk to are aggressively pruning agent memory because storage and per-namespace overhead punishes them for keeping it. With S3 underneath, the calculus flips. Keep the conversation. Keep the embeddings. Keep the per-user behavior log. The next version of your model will probably want it.
When LambdaDB isn't the right fit
I try to be honest about when LambdaDB is the wrong tool, because the wrong fit hurts everyone.
A constant, high-throughput query pattern (say, 1,000 QPS 24/7) doesn't have an idle problem to solve. The pricing math becomes a normal cost-per-request comparison, and you should run it before switching. If you're already happy on pgvector at small scale, don't replace it because a blog post said so. And if you need a feature we haven't shipped, check the docs first. Some advanced re-ranking and graph-style traversal is on the roadmap, not in the product today.
The sweet spot is exactly the shape that's been breaking the existing market: many users, each with their own memory, each idle most of the time. Agent products. Per-user RAG. Coding agents. Any workload where the bill should follow the work, not the calendar.
FAQ
What is a serverless vector database? A vector store where compute is created on each request and destroyed after, storage is billed separately, and idle workloads cost nothing. By that definition, most "serverless" tiers in the market (Pinecone Serverless, Qdrant Cloud, Weaviate Cloud) are managed services with a minimum charge or always-on cluster, not truly serverless.
Why is idle cost a problem for AI agents specifically? AI agents are idle ~99% of the time. They wait for users, webhooks, or schedules. If your vector database has a project-level monthly minimum (e.g., $50/mo on Pinecone Standard) plus per-request metering on top, indie projects pay before they have users. And growth-stage products watch bills scale linearly with usage.
Is LambdaDB a Pinecone alternative? Yes. Built specifically for the workload Pinecone Serverless prices out: many small, mostly-idle namespaces. No monthly minimum, idle storage cost in fractions of a cent, and vector + full-text + filter hybrid search in one query.
How is "$0 idle" possible? The engine runs on per-request compute and per-byte storage. No warm pods to keep alive between requests. When no requests arrive, no compute runs, and you only pay for the bytes your data occupies in storage.
What about cold start latency? Sub-second for typical agent payloads. Platform-level priming keeps user-perceived p99 latency in the same envelope as warm managed databases for write-then-read agent workloads.
How much memory can each agent store? No per-namespace cap that affects pricing. A typical agent (~50 MB of vectors + metadata) costs around $0.001/month idle in storage.
Wake up cheap
If you're building agents, your infrastructure should sleep when they sleep. That sentence sounds obvious until you look at your last invoice.
serverless components is the version of "serverless" that holds up to the test. Idle is free. Namespaces are free. A 1,000-agent product can exist before you raise a round. Cost should follow the work, not the calendar.
Start at $0. No card, no minimum, no warm pod waiting: lambdadb.ai
Technical pieces referenced above: Quickstart · Collections guide · Hybrid search.
Try LambdaDB on your own workload
$0 to start. $0 at idle. Pay per query. First collection in five minutes.